
Abstract
Notes for reading paper Open Source Cross-Sectional Asset Pricing
Main results
(1) 提供了数据和代码,能够成功的复现出几乎所有的截面股票收益预测因子 (provide data and code that successfully reproduces nearly all cross-sectional stock return predictors)
(2) 我们采用的 391 characteristics 来自于之前的元研究 ,然后比较 t-stats 值 (Our 319 characteristics draw from previous meta-studies, but we differ by comparing our t-stats to the original papers’ results)
(3) 在原文献中 161 个比较显著的因子,long-short portfolios 的 t-stats > 1.96. (For the 161 characteristics that were clearly significant in the original papers, 98% of out long-short portfolios find t-stats above 1.96)
(4) 在原文献中 44 个因子的显著性不一致,我们的复现发现 t-stats 的平均值为 2 (For the 44 characteristics that had mixed evidence, our reproductions find t-stats of 2 on average)
(5) 我们复现出的 t-stats 和原文献 t-stats 拟合的斜率为0.9,R^2 为 83% (A regression of reproduced t-stats on original long-short t-stats finds a slope of 0.90 and an R^2 of 83%)
(6) 在特征水平上,预测信号的平均收益是单调的 (Mean returns are monotonic in predictive signals at the characteristic level)
(7) 剩余的 114 个 特征在原始文章中是不显著,其中一部分特征来自于对文章 Hou,Xue,and Zhang (2020) 的修改。 (The remaining 114 characteristics were insignificant in the original papers or are modifications of the originals created by Hou, Xue, and Zhang(2020) )
背景
(1) 学术金融通过开放合作和封闭竞争的混合发展。在本文中, 我们试图通过提供一个包含数百个股票回报预测值的“开源数据集”,将文化推向开放合作。
(2) 开源数据集至关重要,因为最近的研究对整个跨部门资产定价文献的可信度提出了质疑。
(3) 一系列有影响力的评论认为,这些文献中至少有45%的截面资产定价是错误的 (Harvey、Liu和Zhu 2016、Linnainma和Roberts 2018、Chordia、Goyal和Saretto 2020)。 Hou、Xue和Zhang(2020) 更进一步,声称约50%的文献无法复制-即使遵循原始方法
(4) 这一发现意味着许多文献无法在复制中生存,更不用说重新分析了。 这些怀疑反映了从医学到管理等其他领域正在发生的信誉危机
贡献:
(1) 我们的开源数据集为恢复跨部门资产定价的可信度迈出了关键一步。 它表明,近100%的文献可预测性结果可以重现,包括侯、薛和张(2020) 研究的特征的可预测性。
(2) 我们的开源数据集为恢复截面资产定价的可信度迈出了关键一步。 它表明,近100%的文献可预测性结果可以重现, 包括侯、薛和张(2020) 研究的100%特征的可预测性。
(3) 任何有权访问WRDS和Stata的人都可以使用我们的代码自己执行 这种大规模复制https://github.com/OpenSourceAP/CrossSection.
(4) 事实上,我们的代码是以用户为中心编写的。代码是模块化的,因此用户可以快速检查特定特性, 而无需担心大部分代码。代码使用异常处理优雅地移动过去的错误和语义版本控制,使更新易于理解。 最后,我们承诺每年更新这些数据。我们希望这种开放式合作的展示将激励其他人开放他们的分析, 并进一步支持学术金融的可信度
(5) 事实上,缺乏作者提供的数据和代码是张和李引用其复制失败的最常见原因。 相反,我们根本没有使用作者提供的代码,只是根据原始论文中的文本和展示编写代码。
(6) 这些结果表明,先前研究(如Dewald、Thursby和Anderson 1986、McCullough、McGeary和Harrison 2006) 中记录的广泛复制失败可以通过更多的努力来补救。
(7) 与 MCLean and Pontiff (2016) (MP) 相比,我们的复现率很高 M and P 发现他们的97个 predictor portfolios 中的12% 产生的 t-stats < 1.5. 在我们研究的85个预测因子中 (M and P 也研究了这85个因子),其中的 14% lead to t-stats < 1.96, 这些低 t-stats 的 predictors 来源于 “likely predictors”, 值得注意的是我们在这里并不 认为这是 reproduction failure .
(8) 我们的结果与 MCLean and Pontiff (2016) 高度一致。 returns decay post-publication but remain positive , 和MP一样,我们发现,因子在发布后收益衰减,但仍然为正,并且对于样本中更强的预测因子,这种衰减更强。
(9) 我们的结果在定量上与MCLean and Pontiff (2016) 中的结果相似, 即使是那些在我们的因子集中的部分子集是 MCLean and Pontiff (2016) 未研究的。 这些结果与以前的论文相呼应,这些论文在更大的预测集合中复现了MCLean and Pontiff (2016) 的结果 Chen和Zimmermann 2020 ; Jacobs和Müller 2020 。
(10) 我们的研究证明了之前研究”cross-sectional predictability”的文献中的研究是相当可信的。 之前的这些研究包括:out-of-sample tests (MCLean and Pontiff (2016), Jacobs and Müller 2020); multiple-testing adjustments (Chen and Zimmermann 2020, Chen 2020, Jensen, Kelly, and Pedersen 2021 ) 相对于这些论文,我们通过比较reproduction的t-stats和手工收集的t-stats,补充了新的证据,证明cross-sectional文献是极其可复制的。
(11) 一个重要的警告是,我们没有解决文献是否提供可实施的交易利润这一独特但相关的问题。 在一篇密切相关的论文中,Chen and Velikov (2019) 的回答是否定的。 Novy-Marx and Velikov (2016) , chen 和 Velikov 发现 effective bid-ask spreads wipe out most of the post-publication returns for a large set of anomalies. (大部分情况下,有效的买卖价差消除了大部分异象发布后回报。)
方法
Characteristic Selection
- Table1 PanelA:
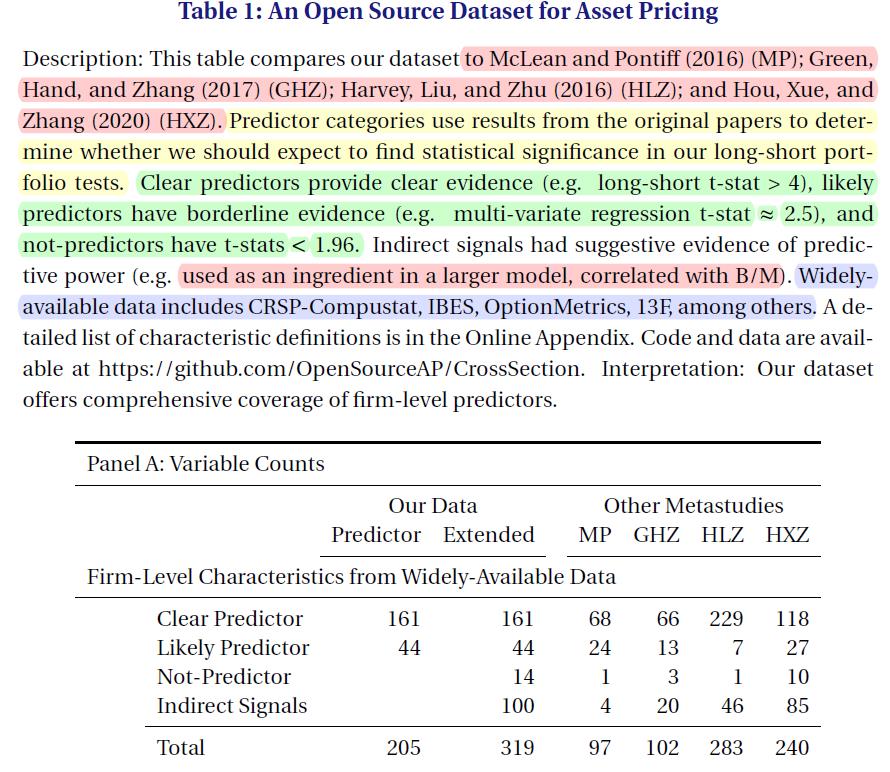
- characteristic 的选择依据于对三个方面的平衡, (1) 全面覆盖之前的研究 (comprehensive coverage of previous mata-studies) (2) 全面覆盖公司层面的截面预测因子 (comprehensive coverage of firm-level cross sectional predictors) (3) 以合理的时间完成高质量的代码和数据 (completion of high quality code and data with a reasonable amount of economist-hours)
- Hou、Xue and Zhang(2020) -> 240 predictors
- MCLean and Pontiff (2016) + Green, Hand, Zhang (2017) -> 49 characteristics
- Harvey, Liu, and Zhu (2016) -> 30 characteristics in firm-level
- total of 319 characteristics drawn from 153 papers.
- 我们没有 cover MCLean and Pontiff (2016) + Green, Hand, Zhang (2017) 中全部的 characteristics 是因为基于我们的第三个考量也就是在合理的时间完成高质量的代码
- 在添加HLZ(Harvey, Liu, and Zhu (2016) )的特征时, 我们要求在原始文件中明确显示该特征,以预测公司层面的股票回报。选择特征时对公司层面的这一要求 排除了许多只以投资组合回报为目标的papers, 因为只以投资组合回报为目标是20世纪90年代之前资产定价论文的一个普遍特征 ( Chan Chen and Hsieh 1985, Chen Roll and Ross 1986 ) 并且这在宏观驱动的文章中更常见 ( Vassalou 2003, Balvers and Huang 2007). 这样的考量是来源于我们的第二个目标:covering firm-level predictors.
- 值得注意的是遵循我们第一个目标,我们不要求对Hou、Xue and Zhang(2020) 、MCLean and Pontiff (2016) 或Green, Hand, Zhang (2017) 的特征具有明确的企业级可预测性。 因此,纯粹基于原始研究的结果,我们的特征在预测能力上有很大差异。
Characteristic Construction
- Table1 PanelB
- 我们尽量紧跟原始文件。我们的目标是 Welch (2019) 意义上的 "复现" (reproductions), 避免重新评估原始论文的有效性。
- 我们认为 extensions 和 reexamination 需要 focused studies(Pontiff and Singla 2019, Novy-Marx and Velikov Forthcoming ), 而这并不适合像我们这样大规模的 meta-study.
- 事实上,正如我们很快解释的那样,我们的大规模研究需要偏离原始论文 , 即使是小规模的研究,完美的复制也是不可能的。WRDS对HML的复制与Ken French的数据具有98.9%的相关性, 但在特定月份,月收益仍有高达1%的偏差(Vora和Palacios,2010)
- 因此,我们的复现(reproduction)可以更好地描述为"尝试复现"(attempted reproduction), 但为了便于阅读,我们通常会在整个文本中删除尝试(attempted)修饰语
- 我们标准化了一些复现流程,以保持文献级结果的透明度以及数据的可用性。
- 所有特征均以每月频率计算,对于更新频率较低的变量,月值是最近观察到的值。 这允许以较低的频率更新投资组合,同时保持替代实现的灵活性。 然而,我们的月度特征意味着我们偏离了少数使用每周再平衡的研究。
- 对于几乎所有特征,我们对年度会计数据可用性使用标准六个月延迟, 对季度会计数据可用度使用标准四分之一延迟。 在一些案例中,我们使用收益报告日期(RDQ)来表示季度数据的可用性,以便更紧密地匹配原始文件。 对于IBE,我们假设在统计期结束日期之前可以获得收益估计。 其他数据假设在原始论文之后可用。由于这种标准化,我们偏离了一些使用更短数据延迟的会计研究
- 许多特征仅在数据的特定子集中显示为预测性。 我们尝试将此子集设置推迟到投资组合生成步骤。 因此,特征代码和数据省略了价格和交换过滤器(filters),这将 而是在投资组合生成中强制执行
- 然而,其他过滤器非常多样化,很难在投资组合阶段实现。 有几篇论文排除了基于SIC代码或缺失会计数据的股票。 还有一些人发现,预测性仅存在于基于特定特征的股票子集中(Piotroski 2000;Elgers、Lo和Pfeiffer 2001)。 为了以可管理的方式容纳这些过滤器(filters), 我们在特征代码中设置了不满足这些过滤器的缺货月份。
- 在少数情况下,我们在 trade off costs and benefits 方面偏离了原始文献。 大多数情况下,偏离原始文章中的结果是因为没有获得原始论文中使用的数据。 例如,Barber et al. (2001) 和 Jegadeesh et al. (2004) 使用了 Zack’s 的 analyst recommendations data (分析师建议数据), 该数据比 IBES 建议的 WRDS 数据更加容易获得。
- 有一些其他偏差更为特殊,我们的predictors 中有一个 predictor 是 “number of consecutive earnings increases” (连续收入增加的次数) 与 Loh andWarachka(2012) 中的 “earning streak predictor”(盈利趋势预测值)相距甚远。
- 我们所有的 “price delay predictors” ( 价格延迟预测因子 ) (Hou和Moskowitz,2005年 ) 都使用单只股票每日收益的滚动回归,而原始论文通常使用两阶段程序,首先估计单只股票价格延迟的噪声度量, 然后通过对第一阶段形成的投资组合进行第二组回归来降低噪声。 我们使用更简单的价格延迟估计,这主要是由于我们的economist-hours预算。
- 这些偏差意味着,在少数情况下,我们reproduced的投资组合与 原始投资组合相差甚远。我们将这些attempted reproductions包括在内,以保持公开性, 我们认为这对本报告的可信度很重要.
Portfolio Construction
- !
- 我们的投资组合数据的核心包括根据原始文献构建的的predictive long-short portfolios。 与其他可预测性研究(predictability studies)一样,我们 隐式假设t月底的 数据可用于在t月最后一天的收盘拍卖中进行交易。 这些是我们在评估 reproduction success 时使用的投资组合。
- 使用原始论文的结果,我们选择股票权重、再平衡频率和分位数排序(如果适用)。 我们手工收集的数据中列出了每个投资组合实现。再一次,为了规范我们的代码和结果, 少数情况下,我们偏离了原始文献构建投资组合的scheme。最值得注意的偏差(deviation)是, 我们使用简单的等权十分位数投资组合来reproduce ([Frazzini和Pedersen(2014)](https://doi.org/10.1016/j.jfineco.2013.10.005) )对beta的押注, 而不是原始构造,其中每个股票根据其beta排名进行加权。
- 我们还提供具有 alternative rebalancing (替代再平衡频率) 和 liquidity screens (流动性筛选) 的投资组合实施, 以及十分位数排序和仅价值加权的投资组合。 我们提醒用户,这些替代实现并没有像原始论文之后的投资组合那样被仔细检查。
- 在我们的基准数据中,我们 sign our portfolios (不 sign 我们的特征), 但 sign our portfolios (签署我们的投资组合)。 也就是说,较高的特质波动率特征意味着较低的平均回报, 但相应的多空组合具有正的平均回报。 手工收集的数据具有这种 sign information (符号信息),如果这种信息适合用户的应用, 用户可以将其应用于变换特征。 为简单起见,如果原始文件未提供正确 sign 的直接证据,我们不会 sign 投资组合。 (这里的 sign 应该就是指买入或者卖出)
Predictability Categories
- Figure1
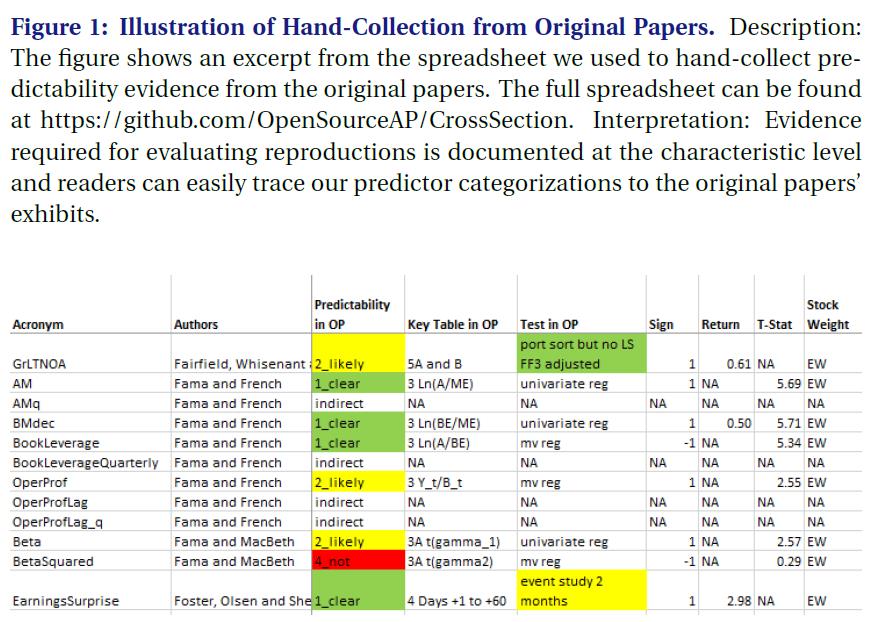
- 为了确定可预测性类别,我们将原始论文的结果与我们的 characteristic reproduction (特征再现代码)进行比较。
-
关于原始论文的结果是手工收集的。我们手工收集了 key table (关键表格), demonstrating predictive power(展示了预测能力)、the empirical test used (使用的实证检验)、 the sign of predictability (可预测性符号)、 mean return (平均回报)、t-stat、 individual stock weighting (个股权重)、 portfolio sort quantile (投资组合排序分位数)、rebalancing frequency (再平衡频率)等。 图1显示了我们的电子表格的节选以供说明。 全部的表格信息可以点击链接: https://github.com/OpenSourceAP/CrossSection/raw/master/SignalDocumentation.xlsx.
- 我们将收集的特征分为4类(we assign our characteristics to four categories):
(1) ‘Clear Predictor’: is expected to achieve statistically significant mean raw returns in long-short portfolios (e.g. t-stat > 2.5 in a long-short portfolio, monotonic portfolio sort with 80 bps spread, t-stat>4 in a regression, t-stat > 3 in 6-month event study )
(2) “ Likely Predictor”: Our characteristic is expected to achieve borderline evidence for the significance of mean raw returns in long-short portfolios (e.g. t-stat=2.0 in long-short with factor adjustments, t-stat between 2 and 3 in a regression, large t-stat in 3-day event study.)
(3) “Not-Predictor”: Expected to be statistically insignificant in long-short portfolios (e.g. t-stat=1.5 in long-short, t-stat=1 in a regression)
(4) “Indirect Signal”: Only suggestive evidence of predictive power (e.g. correlated with earnings/price, modified version of a different characteristic in-sample evidence only).
-
将 characteristic 进行分类对评估 reproduction success 是必要的。 对于 clear predictors , t-stat>1.96 identify the success. 对于 not-predictors , t-stat < 1.96 is indicative of success.
- 对于 Likely Predictor 和 Indirect Signal , 测量它们的 reproduction success is more subtle (微妙的)。 一些 “ Likely Predictor ” 的 t-stat very close to 1.96. 鉴于数据更新肯定会使t-stat上升或下降,因此,reproduction的t-stat高于或低于1.96的概率应为50/50。
- 类似地,如果原始论文在univariate regression(单变量回归) 中发现t-stat为2.6,则很难说reproduced long-short portfolio(复现多空组合) 是否也会产生t-stat>1.96。
- “Likely predictors:” 另一方面,我们的 characteristics code 和 原始论文的偏差也会导致产生 “Likely predictors”, 这就需要进行微妙和谨慎的判断。
- “Indirect signals”: 同样也是充满技巧的。 我们的大多数的 “Indirect signals” 是来自于对 其他特征的修改,这样的修改是否应该增加或者减少 t-stat 需要判断。
- “Indirect signals”: 使问题复杂化的是,一些 “Indirect signals” 来来源于对 “likely predictors” 和 “Not-Predictors” 的修改,这意味着需要多个判断步骤来确定我们的 long-short portfolio 应该落在 t-stat = 1.96 的哪一边。
- 对 characteristic 的分类是有帮助的,因为分析 “clear predictors” 和 “likely predictors” 的方式和分析 other characteristics 的方式不一样。 (This separation is helpful because of clear and likely predictors are quite distinct from the other characteristics in how one should analyze them.)
- 事实上,我们的 “Not-Predictors” 和 “Indirect-Signals” 大部分都来自于 Hou, Xue, and Zhang (2020).
Literature-Level Reproduction Performance
Success of Predictor Reproductions
- Figure2
我们评估 reproduction success 来自于一个简单的 指标:long-short raw return t-stat 是否大于 1.96. 这一指标是 Hou Xue and zhang 文章中主要使用的观测方法, 提供了一种对 reproduction success 简单的易于理解的测量方法。 图2 显示了 t-stat > 1.96 的 “clear predictors” 所占的份额 data 分类为 accouting, analyst forecasts, corporate events, stock prices, trading data.
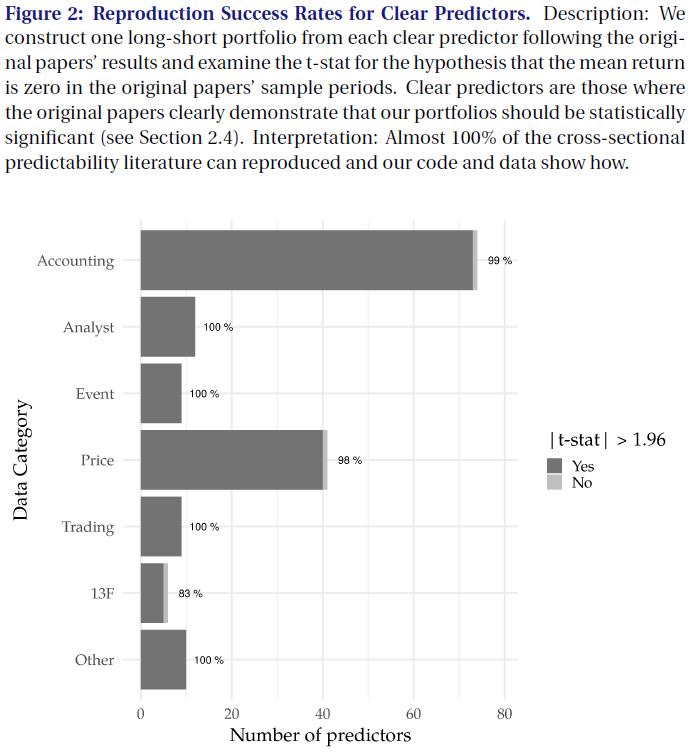 图2显示了我们的 reproduction对 “clear predictors” 是非常成功的
图2显示了我们的 reproduction对 “clear predictors” 是非常成功的 - Figure3
有人可能会担心,我们极高的 reproduction success rate 会对我们如何定义 “clear predictor” 非常敏感。 类似的,人们可能会担心,即使我们复现得到的 t-stat > 2.0 , 但是其实在原始论文中比 2.0 小得多。图三的结果 可以解决这两种担忧,通过简单地绘制 reproduced t-stats与原始论文的t-stats.
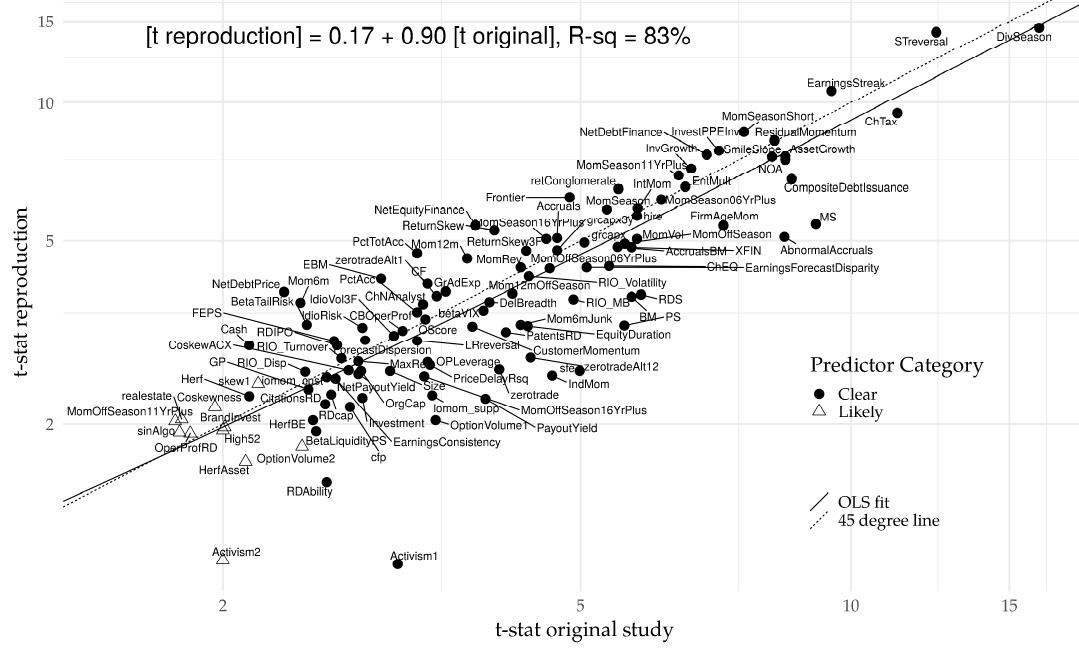
- 图3 说明了我们极高的 reproduction success rate 对 predictor categorizations 不敏感
- 与原始论文一致,我们的reproduction 也会产生接近2.0的t-stats, 尽管其中大约一半低于任意的1.96阈值。更广泛地说,我们对于”clear predictors”的极高成功率 并不是由于t-stats刚刚超过2.0。许多重复的t-stat超过5.0,少数甚至超过10.0。
- 也许最重要的是,图3显示,我们的reproduction与原始结果不仅在定性上匹配,而且在定量上匹配
- 在原始t-stats上回归我们的reproduction t-stat产生的系数为0.90,离理想斜率1.0不远。R2为83%, 这意味着reproduction不会偏离原始值太远。事实上, 剩下的大部分 deviations 可能是由于我们的t-stats使用 simple raw mean long-short returns (简单的原始平均长-短回报率), 而许多原始论文中的t-stat 根据特征或 factor exposures (因子暴露) 进行调整 。
- 作为横截面文献 reproduction 的最终证明, 我们检验了预测因子的平均收益率是否单调。 根据我们的经验,显示投资组合排序的绝大多数论文也显示出单调性,尽管我们没有手工收集这些信息。
- Figure4
有趣的是,图4还提供了反对p-hacking可预测性解释的证据。 对于 p-hacking 解释可预测性,p-hacking必须在整个预测分布范围内操作, 从一个 level of the predictor 到下一个水平递增平均回报. 这种微调是一个在以往模拟p-hacking的研究中没有研究过的问题。 (Harvey Liu and Zhu (2016); Chen and Zimmermann (2020); chen 2020 ), Hou Xue Zhang (2020) 也没有检验过 p-hacking 问题。
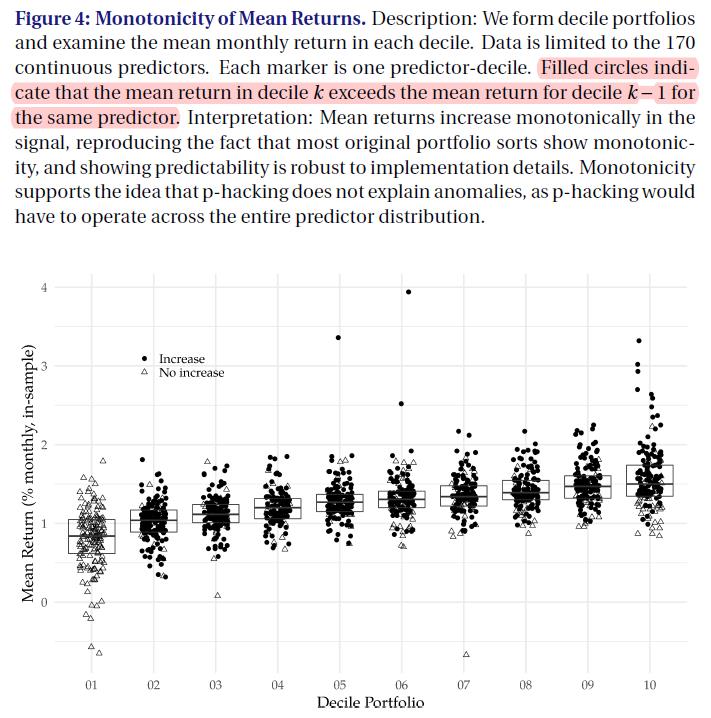
这就是我们的主要结果。几乎100%关于股票收益率可预测性的文献都可以复制。 这一发现不仅意味着文献的真实性,而且更普遍地捍卫了资产定价界的可信度。
Not-Predictors, Indirect Signals, and Comparison with Other Meta-Studies
- !
我们 reproduction 的巨大成功似乎与文献不符。 McLean和Pontiff(2016)(MP) 发现,他们的 97个预测因子中有12%产生t-stats<1.5,表明“失败率”远高于我们的主要结果。更引人注目的是, Hou、Xue和Zhang(2020)(HXZ) 发现,他们的452个long-short 投资组合中 约有50%产生的t-stats绝对值小于1.96,即使权重相等,且仅限于原始论文的样本期。
我们的结果与McLean Pontiff(2016)(MP) 和 Hou、Xue Zhang(2020)(HXZ) 不同, 主要是因为我们仔细检查了原始论文,在判断 reproduced long-short t-stats 是否应该超过 1.96 这一问题上, 我们仔细检查了阈值的适用情况,也就是阈值 1.96 是否适用于当前的 predictors. 相比之下,McLean Pontiff(2016)(MP) 有一个更宽松的标准,仅限于“在5%的水平上拒绝零回报可预测性”的论文。 HXZ更宽松。HXZ表示,他们的“清单包含了大部分已发表的财务和会计 异象文献”, 但没有具体说明我们可以确定的更多纳入要求。
- Figure5
我们的仔细检查如图5所示,图5显示了所有特征(包括“Not-predictor”和“Indirect Signals”类别中的特征) 的再现t统计量的抖动图。 前两行回应了图2和图3的结果:“Clear Predictors”几乎一致地具有t-stats>1.96,并且许多t-stat要大得多。 “Likely Predictors”预测值大致均匀地分布在1.96左右。 值得注意的是,这些数据中包括了基于regression 和event study 验证了的 Predictors,因此涵盖的 “Likely Predictors” 远高于图3。
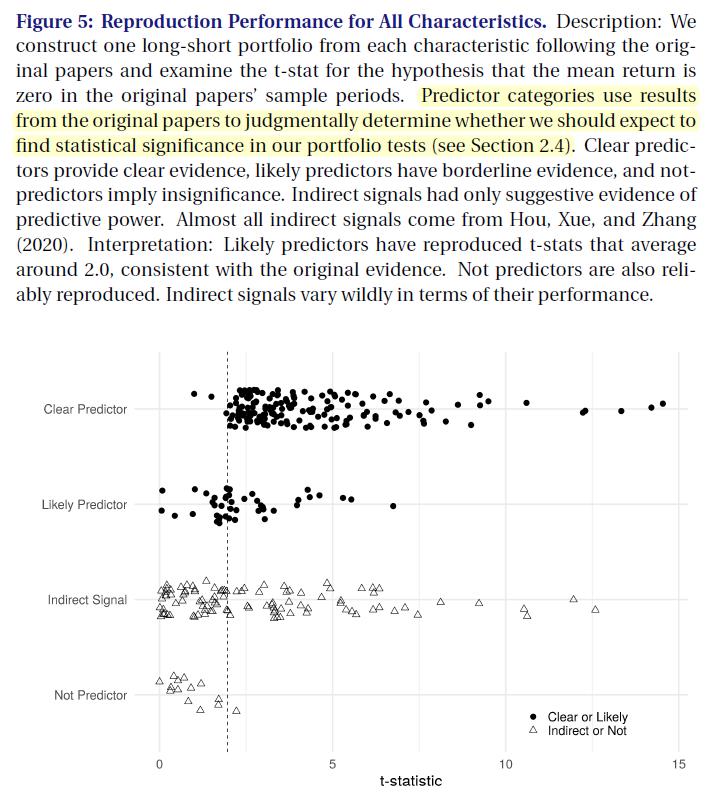
- 与”Clear Predictors”和 “Likely Predictors” 因子不同, “Not Predictors”和 “Indirect Predictors” 通常无法在我们的 reproduction 中达到统计学意义。 大量 “Indirect Predictors” 位于t-stat=1.6的左侧,几乎所有”Not Predictors”都位于同一区域。
- Figure6
图6显示了类似图5的图,仅限于同样出现在McLean Pontiff(2016)(MP) (顶部Panel)或Hou、Xue Zhang(2020)(HXZ) (底部Panel)中的预测值。
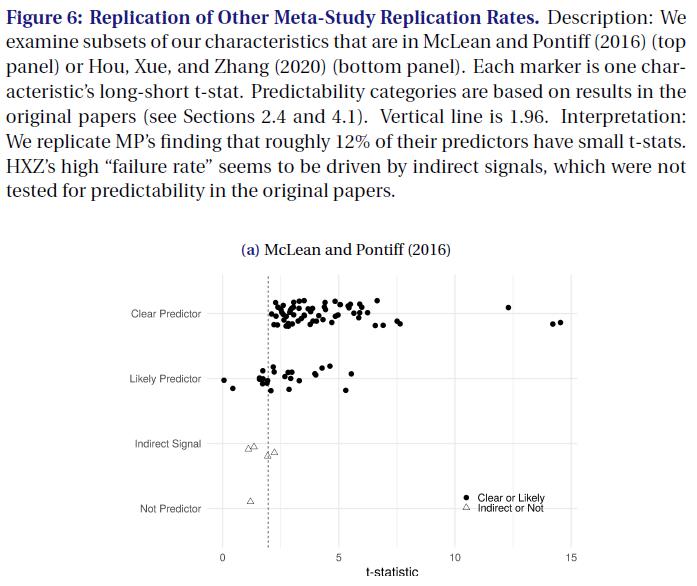
- 顶部面板与 McLean Pontiff(2016)(MP) 的发现相呼应, 即约12%的预测值具有较小的t-stats。我们的85个特征中有14个与MP重叠,其t-stats<1.96(虚线)。
- 我们将其中的大多数判断为 “Likely predictor” factor,少数判断为”Indirect signal”,一个判断为”Not Predictor”。
- 特别是,我们将 Dichev(1998)的Z-score 判断为”Not Predictor”,因为它在 univariate regression (单变量回归)中发现t-stat为1.59(见Dichev的表3A)。
- 然而 McLean Pontiff(2016)(MP) 很可能包括了 Z-score, 因为其在具有size 和B/M对照的多元回归中t-stat为3.37。
- 然而,我们认为,我们 reproduced Z-score 的 t-stat 为 1.20 不应被判断为再现失败, 因为它与Dichev的 univariate regression (单变量回归)结果非常一致。
- 图6的底部面板显示了与Hou、Xue Zhang(2020)(HXZ) 重叠的predictors。 数据看起来与我们的完整数据集非常相似(图5): “clear predictors”几乎完全高于1.96, “Likely predictors”集中在1.96左右,而不是低于1.96的预测值,”Indirect Signals”分散, 但大部分信号低于1.1996。因此,[Hou、Xue Zhang(2020)(HXZ)](https://doi.org/10.1093/rfs/hhy131) 大约50%的故障率似乎是由于 abnormal (“异象”) 的错误分类。
- 在我们的reproduction中,几乎所有明显的失败都与这些 predictability 没有被证实的研究论文有关
- 重要的是,McLean Pontiff(2016)(MP) 选择在确定原始研究 predictability 时更为宽松,这对于他们的研究目标是完全有效的。 MP试图测量 样本外可预测性的下降幅度,对于未达到1.96临界值的 predictor,人们可能会对这种下降感兴趣。
- Figure7
事实上,我们发现,即使我们限制了我们的研究只在 “clear predictors” 的样本上, 我们也可以密切reproduce McLean Pontiff(2016)(MP) 的结果。 这种稳健性如图7所示,它仅使用“clear predictors” 复制了图1(MP)的结果。 顶部面板绘制in-sample return(样本内收益)与post-publication(发布后收益)衰减的关系, 底部面板为 in-sample t-stat return 。在这两个面板中,我们将数据子集化, 以区分 MP(暗圈)中的“clear predictor”,不存在 MP(亮三角形)中的” clear predictor”。
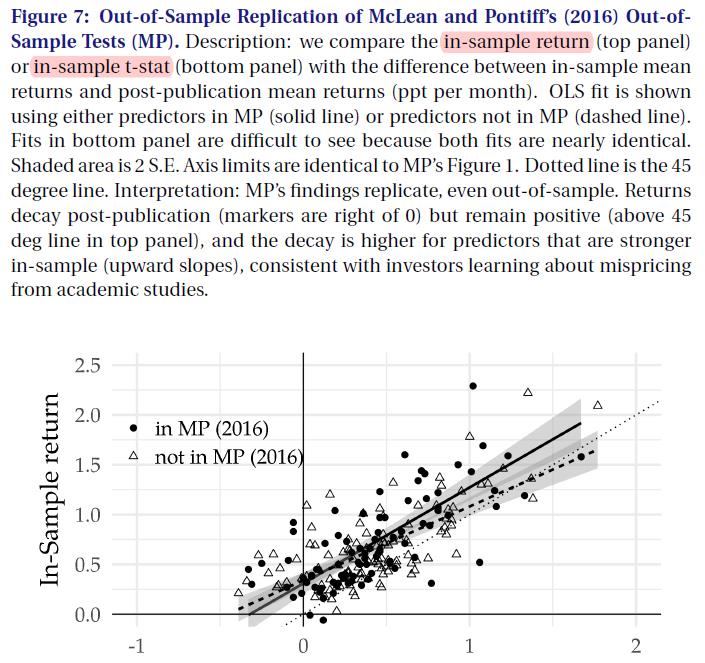
- 该图证实了关于 post-publication decay 的三个重要事实: (1) decay increase in the in-sample return (2) decay increases in the in-sample t-stat (3) the decay is not large enough to wipe out the in-sample return.
- (1) decay increase in the in-sample return 可以由图中回归线向上的斜率看出。
- (2) decay increases in the in-sample t-stat 可以由图中回归线向上的斜率看出。
- !!! 值得注意的是斜率向上还是向下并不取决于 whether we fit the regression to predictors that are studied by MP (solid) or missing from MP (dashed)
- !!! 事实上两个标准差 bands overlap 的非常多,这说明 MP 的发现在 out-of-sample test 中也会 定量的成立 ( hold quantitatively) 。
- (3) the decay is not large enough to wipe out the in-sample return 可以通过比较 predictor markers 和 45 degree dotted line 比较来看出来。如果 post-publication decay 足够强能够 wipe out in-sample returns, then the predictors would be evenly distributed around this 45 degree line. However, the majority of predictors lie above the 45 degree line, showing that predictability survives post-publication. </font> 值得注意的是这里没有考虑交易费用 (It is important to note, however, that these results do not account for trading costs).
- 总的来说,我们的结果似乎与其他研究不同,因为我们根据原始结果 仔细分类预测因子。只有通过这种谨慎的分类,meta-reserach 才能准确评估reproduction 在如此大规模上是否成功。 这些分类不影响McLean和Pontiff(2016) 分析, 事实上,我们在具有更高标准的“predictors”中reproduced了他们的结果。
Characteristic-Level Reproduction Performance
- 概述
- 在文献层面的结果背后是319个企业层面的特征,每个特征都有自己的故事, 原始统计数据,和 reproduction quality (复现质量). Tables 2-4 探讨了这一丰富的数据,列出了每个个体特征,reproduced mean return (复现的平均收益率), t-stat, 以及原始论文中 evidence for predictability (可预测性证据) Table2 -> ‘Clear Predictors’; Table3 -> ‘Likely Predictors’; Table4 -> ‘Not Predictors and Indirect signals’
Which Predictors Are “Clear”, “Likely”, or “Not”? Which are “Indirect Signals”
- Categorization Details for Clear and Likely Predictors
- “Clear Predictors”: Most clear predictors produced t-stats that > 2.5 in long-short portfolio in the original papers (出现在原始论文中的 clear predictors)
- “Clear Predictors”: 除掉在原始论文中出现 clear predictors,剩余的 clear predictors 大部分产生的 t-stats > 4
- “Likely Predictors “: 大多数的 “Likely Predictors” 在原始文献中的 t-stat 是微不足道的。 其余的 “Likely Predictors” 的 predictability 是模糊的。[Amihud and Mendelson (1986)] bid-ask spread predictor showed strong portfolio sorts, but the original paper did not provide a long-short t-stat. (之前研究的一些文献,尽管给出了 strong portfolio sorts 但是没有给出 t-stats 值).
- [Huagen and Baker (1996)] 文章中给出了一些predictors 基于 180 个不同的多元回归的 t-stat 值。 但是这很难说明是否会在 long-short portfolios 中产生大于 2 的 t-stats
- Categorization of Not-Predictors and Indirect Signals
- 大多数的 “Not-Predictors” 的 t-stats < 1.96 in long-short portfolio in the original studies [Ang, Chen, and Xing’s(2006) past downside beta; Anderson, Ghysels, and Juergens’s(2005) long-term forecast dispersion; Whited and Wu’s(2006) financial constraints index]. 值得一提的是,这种意义的缺失不应被视为对原始论文的批评。5%的显著性临界值是任意的, 其中一些预测值刚好低于临界值。
- Indirect Signals: 许多“Indrect Signals”在最初的论文中根本没有可预测性证据。 权责发生制质量、收益稳健性和收益价值相关性都来自Francis等人(2004年), 他们研究与基于价值线价格目标的隐含资本成本估计相关的特征
- 其他”Indirect signal”来自原始论文中与可预测性相关的信息, 但我们认为这一证据太弱,无法判断投资组合类别的统计显著可预测性。 一些 weak evidence 来自于 [Acharya and Pedersen’s (2005)] 对 liquidity betas 的研究。 [Acharya and Pedersen’s (2005)] 基于 betas in GMM framework 来 estimate market price of risk, 基于 GMM framework, if the parameters are very stable, which would imply predictability. 由于[Ang, Chen, and Xing 2006] 中的 betas tend to be unstable, 我们认为这样的 GMM results as close to no evidence regarding the results of portfolio sorts, 同样,我们判断[Abarbanell和Bushee(1998年)] 和[Soliman(2008年)]的 multi-variate regressions (多元回归) 在回归系数不显著时提供的信息不足 (provide insufficient information for our purposes when the coefficient on a regressor is insignificant)
- “Indirect signals” 的主体来自于 Hou、Xue Zhang(2020)(HXZ), 这些特征我们标记为 “HXZ variant”, 大多数小的修改是采用了年报的季度版本(Most of these modifications use quarterly versions of annual accounting variables), 很少的一些 “Indirect Signals” involve arbitrary lags of the denominator or using alternative factor model adjustments when generating return residuals (当产生残差时,采用可替代的因子模型)
- 我们避免对 HXZ variants 进行分类,因为这里面需要一些微妙的判断。 例如,HXZ’s produce a quarterly version of [Whited and Wu (2006)], which produced a t-stat of 1.2 in the original paper. It's very hard to say whether a more timely version of this variable would lead to statistical significance, Similarly, it's hard to say if a quarterly version of an annual accounting-based variable will have too much seasonality to be predictive. (类似地,很难说基于年度会计的季度变量是否具有太多的季节性而无法预测。) The seasonality would depend on the precise details, and we did not want to exercise this much judgment. We decided, therefore, to simply label all of HXZ’s variants. (季节性将取决于准确的细节,我们不想做这么多判断。 因此,我们决定简单地将HXZ的所有变量标记为“Indirect Signals”。)
- 对表4的检查表明,几乎所有HXZ variants 都证明了原始结果的稳健性 (robustness)。 [Chan、Lakonishok和Sougiannis(2001)]发现,从研发到销售无法预测回报, 我们对 HXZ variants 季度版本的 reproduction 也无法达到统计意义。 同时,我们reproduce了HXZ对[Anderson和Garcia Feijoo(2006年)]capx growth、 [Ball等人(2016年)] 基于现金的运营盈利能力以及 [Lakonishok、Shleifer和Vishny(1994年)]的市场现金流的变化, 这些都具有统计意义,与原始结构一致。
Reproduction Failures and Struggles
- 概述
- 尽管总体上取得了压倒性的成功, 表2和表3说明了我们的reproduction在少数情况下是如何 struggle 甚至 fail的。 正如导言中强调的,这些失败不应被视为对原始论文的批评, 因为在我们数百个reproduction 特征中很可能存在编码错误或 remaining deviations (剩余偏差)。
- 在我们”Clear Predictors”中(表2), 最小的reproduced t-stat是[Cremers和Nair(2005)](CN)的 takeover vulnerability(收购脆弱性)。 我们的t-stat只有1.00,平均回报率为每月25个基点,然而最初的论文发现t-stat为每月3.1个基点,alpha为每月90个基点。 我们的reproduction 使用 raw mean returns (原始平均回报率), 而 [Cremers 和 Nair] 使用[Carhart(1997)]的四因子阿尔法, 所以也许这种 deviation (偏差)是导致结果 difference (差异)的原因。 然而,我们通常会发现,因子调整的影响相对较小(图3), 我们也很难reproduc [Cremers 和 Nair ]的 active shareholder predictor (积极股东预测因子), 我们将其归类为“Likely predictors”如表3所示, 我们的reproduction 产生的t-stat为1.02,而原始的t-stat为2.04。
- 第二个最小的t-stat来自我们对[科恩、迪瑟和马洛伊(2013)] R&D ability(研发能力)的reproduction。 与原稿的t-stat为2.6相比,我们的reproduction获得了1.50的正t-stat,但不显著。 [Cohen、Diether和Malloy] 通过对 sales forecasting model (销售预测模型)的滚动估计来衡量研发能力, 该模型 involves several lags of R&D (涉及几次研发滞后)。 因为研发容易缺失,如果为零值, 我们很可能没有遵循与原始作者完全相同的程序。
- “Clear Predictors”: 在我们”Clear Predictors”中,唯一t-stat<1.96的是 [Pástor和Stambaugh(2003)] 的流动性β。 然而,我们reproduced 的t-stat为1.93,仅比任意截止值1.96低一点点, 与原始CAPM调整后的tstat 2.5相差不远。 我们应该注意的是,我们的目标只是reproduce [Pastor和Stambaugh], 其他reprodcution 论文发现该预测因子对构造细节敏感 ([李、诺维·马克思和Velikov 2019];[Pontiff和Singla 2019])。
- 另一个表现不佳的 reproduction 是[Elgers、Lo和Pfeiffer(2001)] 的 earnings forecast to price (收益与价格预测), 在我们的数据中,该预测的t-stat为2.6,远低于原始的t-stat 5。 然而,原始的t-stat进行了大小调整, 本文中的其他表格也显示了其数据中的重大size效应。
- 值得一提, 最后一个 struggled “Clear Predictos”来自我们对[Boudoukh等人(2007)] 的 payout yield portfolio (支付收益率投资组合)的reproduction。 对于这个Predictor,我们选择了一种微妙的方式来偏离原论文。 在原始论文的最后,作者提出了一个long-short策略, 从带有纽约证券交易所断点的tercile排序中产生了3.92的t-stat。
- “Likely Predictors”: 在”Likely Predictors”中(表3),大多数明显的reproduction 失败 仅仅是由于我们的 reproduction attempts 与原始论文之间的(deviations)偏差。 [Amihud和Mendelson(1986年)]、[Barber等人(2001年)]和 [Barry和Brown(1984年)]都使用了我们无法访问的专门数据集(见第2节)。 我们也没有使用[Abarbanell和Bushee(1998年)]的多元回归, [Haugen和Baker(1996年)]使用的180个多元回归的总和,或 [Frazzini和Pedersen(2014年)]使用的专门投资组合分类。
- “Likely Predictors”: 在reproduction 困难方面, 最显著的可能预测因子来自[Frankel和Lee(1998)]。 本文使用分析师预测和现值模型生成了三种交易策略,并进行了重现。 我们的reproduction导致t-stats介于0.96和2.01之间, 尽管原始论文发现总体上有1%的统计显著性。 然而,这种高度的统计显著性是“通过蒙特卡罗模拟得出的”, 很难与它们较小的收益利差和较短的15年样本相符。 事实上,我们发现在他们的样本中,B/M的显著性远低于他们使用RMONTE Carlo检验显示的高显著性。 简言之,我们将较小的t-stats归因于方法上的偏差, 而不是reproduction 失败,但理性的人在如何评估这些reproduction上可能存在分歧。
Extremely Strong Predictors
- 概述
- 图3显示,许多reproduction实现了6.0或更高的t-stats。相应的p值为0.000000002, 这意味着这些预测值不太可能从无可预测性的空值中获取的。 事实上,[Chen (Forthcoming)]认为,仅从p-hacking一项, 预计至少需要400年才能产生这些预测值。 与这一观点一致,[哈维、刘和朱(2016)]的SMM估计以及 [Chordia、Goyal和Saretto(2020)]的校准表明,t-stats超过4.0几乎 可以保证是真正的发现。
- 表2更仔细地研究了这些预测因素。几乎所有这些杰出的预测指标都关注会计数据、 分析师预测或股价。 换言之,几乎没有一个来自更奇特的数据类别。
- 这些杰出的performance是多种多样的。 其中包括 earnings surprise streaks (收益意外连胜(Loh和Warachka,2012年)); net external financing (外部融资净额(Bradshaw、Richardson和Sloan,2006年))、 Change in recommendation (建议变化(Jegadeesh等人,2004年))、 return seasonality (回报季节性(Heston和Sadka,2008年))、 conglomerate return (企业集团回报(Cohen和Lou,2012年))、 dividend seasonality (股息季节性(Hartzmark和Solomon,2013年))、 employment growth (就业增长(Belo、Lin和Bazdresch,2014年))、 asset growth (资产增长(Cooper、Gulen和Schill,2008年)), change in taxes (税收变化(Thomas和Zhang,2002年)),以及 enterprise multiple (企业多元化(Loughran和Wellman,2011))。 这些 predictors 缺乏任何明显的经济联系,这与我们在”clear predictors”中 发现的接近零的中值相关性(near zero median correlation)一致(第5.1节)。 然而,如表2和图3所示,这些预测因子在原始论文中确实具有非常大的t-stats。
Additional Evidence of Dataset Quality
- 概述:
- 本节提供了有关数据集质量的其他结果。 我们将此分析限制在205个 “Clear Predictors” 和 “Likely Predictors”。 简而言之,我们将”clear-“和”Likely-“的”predictors”称为“Predictos”。 我们在这里关注”Predictors”,因为评估”Non-Predictors”和”Indirect Signals”的质量要复杂得多。
- 在选择特征时,我们的目标主要是全面覆盖先前的 meta-studies 元研究。We make no attempt to eliminate predictors due to subjective similarities。
- 我们纳入了几个与盈利能力相关的预测因素, 包括来自Fama, French(2006) 的 Predictor;Balakrishnan, Bartov, Faurel(2010年) 还有 Novy-Marx (2013). 对不同的预测因子持开放态度是必要的,因为 到目前为止,还没有确定不同预测因子的既定方法。通过包含所有预测因素, 我们允许我们的代码和数据的未来用户自行确定哪个版本的盈利能力是“正确的”。
- 尽管存在这种 potential redundancy(潜在的冗余),
但一项简单的分析表明,该数据集是非常高维的。
图8通过显示相关性的分布来检验这个问题。
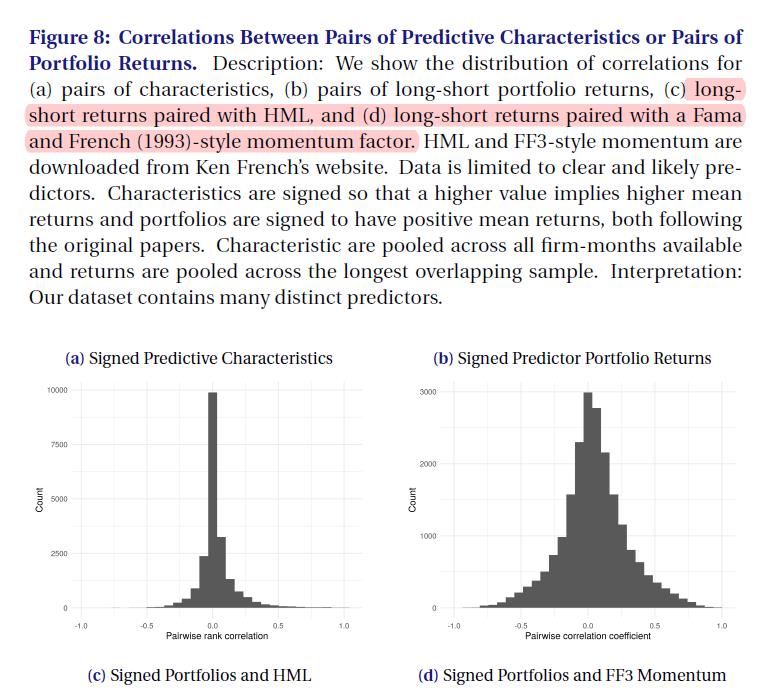
- 面板(a)显示了特征水平的相关性。 它显示了股票水平预测因子(特征)之间的 pairwise ranl correlations (成对秩相关分布)。 在计算相关性之前,我们对所有预测值进行签名,以便根据原始论文,预测值越高意味着平均回报越高。 面板显示,预测值水平的成对相关性通常接近于零, 这表明预测值包含不同的信息。 这些结果与[Green、Hand和Zhang(2013)]一致, 他们在39个易于编程的预测因子中发现了接近零的相关性。
- 面板(b)显示,这种高维度延伸到投资组合层面。 它还显示了 distribution (成对相关性的分布), 这次使用了一对long-short组合回报。 与我们所有的long-port预测投资组合一样, 根据最初的论文,投资组合被sign为具有正平均回报。 与预测相关性类似,大部分分布的投资组合收益相关性接近于零。 事实上,绝大多数相关性介于-0.5和+0.5之间。
- 面板(c)和(d)检查HML和动量因素是否包含我们的多空投资组合。 HML和动量因子都来自Ken French的网站,并根据Fama和French(1993)的2×3排序构建。
- 面板(c)显示, 我们的少数投资组合与HML的相关性为0.6或更高, 但大部分相关性分布仍接近于零。 图(d)显示了动量因子的类似结果。 总体而言,我们的多空投资组合包含许多不同的策略, 这与McLean和Pontiff(2016) 的发现一致, 即其reproduced回报之间的平均相关性接近零。
Peformance by Liquidity Adjustment
- 概述:
- 遵循我们的“reproduction”理念,我们的基准投资组合尽可能遵循原始论文。 然而,这些投资组合可能高估了交易者从这些预测中可能获得的利润, 因为其中大多数都是同等权重的(Green、Hand和Zhang 2013)。等权投资组合需要交易 非流动性股票和巨大的交易成本(例如,Novy Marx和Velikov 2016)。
- 图9考察了简单的 Liquidity adjustments (流动性调整)如何影响预测性能。
该图显示了in-sample mean returns(样本内平均回报)的抖动图,
将原始数据的 adjustments (调整)(如果有的话)与
各种流动性屏幕以及 enforcement of value-weighting
(价值加权的实施)进行了比较。
The original liquidity adjustments(原始流动性调整)可在我们的手工收集数据中找到,
网址为:https://github.com/OpenSourceAP/CrossSection.
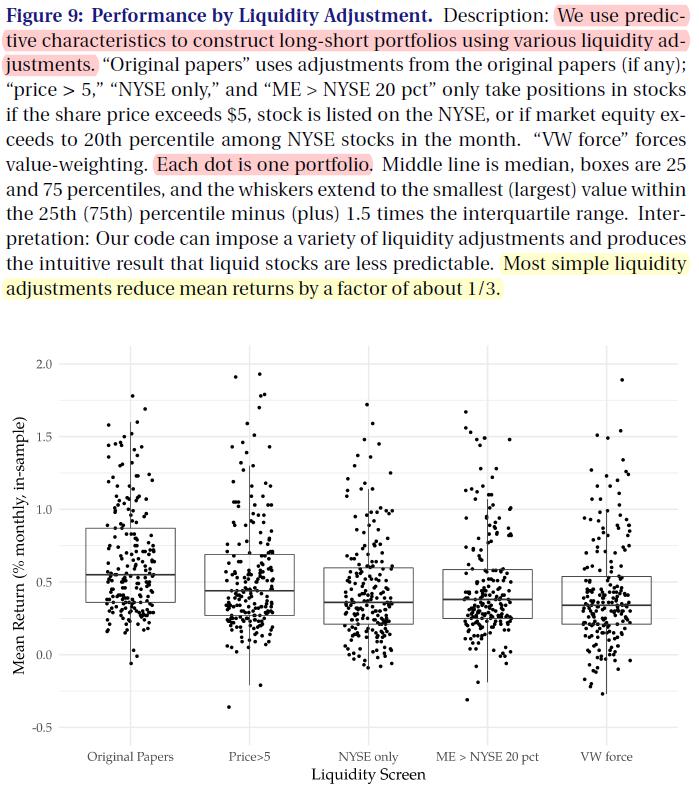
- 直觉上,所有流动性调整都会导致较低的平均回报。 价格筛选(仅限于股价为5美元的股票)似乎是最软的调整, 表现下降幅度最小。其他流动性调整具有相对类似的效果。
- 总体而言,简单的流动性调整将平均回报率平均降低了约1/3。 典型的平均回报率从每月约60个基点降至每月约40个基点, 无论调整是仅纽约证券交易所的筛选、市场股票筛选还是价值加权的实施。 这些结果在数量上与[Chen和Velikov(2019)]相似, 他们发现有效的买卖价差消除了样本中约1/3的平均回报,即使在成本降低后也是如此。
- 图9还说明了我们代码的灵活性。 这些不同的屏幕之所以成为可能, 是因为我们试图将强制屏幕推迟到投资组合生成步骤。 因此,用户可以选择是从所有股票中获取信号,还是只从流动性更强的股票中获取。
Performance by Rebalancing Frequency
- 概述
- rebalancing 我们的代码还允许灵活选择再平衡频率。 更准确地说,该代码允许用户选择将股票重新分配到投资组合的频率。 根据cross-sectional文献,我们称之为 rebalancing(再平衡)。 例如,在计算交易成本时,这种灵活性可能很重要。
- 图10显示,当我们改变rebalancing (再平衡频率)时,我们的代码会产生直观的结果。 该图绘制了1、3、6和12个月再平衡预测值的平均回报分布。 为了进行比较,我们还显示了原始论文中使用再平衡频率的结果。
- 与原始规范相比,每月重新平衡导致平均回报略高。 这是因为许多原始论文遵循Fama和French(1992年)并每年(每年6月)重新平衡。
- 随着再平衡频率从1个月减少到12个月,性能单调下降。 这种模式是直观的,因为较不频繁的再平衡意味着较少暴露于预测信号。
Conclusion
- 概述
- 截面资产定价的可行度令人怀疑(The credibility of cross-sectional asset pricing is in doubt)。 几篇论文认为, 由于不再依赖有效的统计方法,许多文献是错误的 (Harvey, Liu, and Zhu 2016; Linnainmaa and Roberts 2018; Chordia, Goyal, and Saretto 2020 ), 在一个引文量非常高的论文中,作者指出即使遵循原始的文献,不仅是统计方法无效, 而且数字也无法被复现出来(Hou、Xue Zhang(2020)(HXZ) ) 。
- 我们提供的数据和代码是恢复文献可信度的关键一步(We provide data and code that takes a key step toward restoring the credibility of the literature). 数据显示,近100%的文献可预测性结果是可以 reproduction的,我们大程序代码 显示了这一令人惊讶的结果是如何实现的。这种可靠性增加了 cross-sectional 文献是相当可信 的证据(McLean和Pontiff(2016) Jacobs and Muller 2020, Chen and Zimmermann 2020, Jensen, Kelly, and Pedersen 2021 )。
- 我们的代码是以用户为中心显式编写的。 该结构是模块化和并行的,因此,尽管整个软件包规模庞大, 但代码片段可以很容易地固定或改进。 我们欢迎用户通过访问https://github.com/OpenSourceAP/CrossSection. 我们希望这种开放合作的展示能激励其他人开放他们的分析。 在我们看来,向开放的转变不仅对专业人士理解风险和回报很重要, 而且对保护学术金融在广大公众眼中的信誉也很重要。